ML Model with Automated Creation

This is a part of the series of blog posts related to automated creation of Machine Learning Models, and Datasets used for training algorithms. If you are interested in the background of the story, you may scroll to the bottom of the post to get the links to previous blog posts. You may also head to Use SERP data to build machine learning models page to get a clear idea of what kind of automated machine learning models you can create.
In the previous week we showcased how to utilize SerpApi’s Google Images Scraper API to get a clear dataset to reduce noise in training machine learning models, alongside how to automate the use of chips parameter. This week we will discuss about how to automate the creation of algorithms for machine learning models training. Just like previous weeks, optimization of training will not be the main concern. The aim is to get as close as we can get to automated machine learning.
Can ML be automated?
Yes, it is possible to create a clear dataset at scale, automate the creation of machine learning models with different hyperparameters, test them, and compare the results to get the best algorithm with best optimization.
This process is deeply connected to interpretability of the work of data scientists and software engineers, and effective visualization of the training processes, neural networks, and metrics. General automation is limited due to a fundamental problem. Libraries written for data science is not optimized to automate the process at scale. There are other solutions such as automl, which is limited to its own scope. A general automated machine learning with multiple library supports and automatic clean dataset creation hasn’t been out there yet. We aim to make this work, and make it an open source project for data scientists, software engineers, and everyone who is interested in the topic.
What are the main 3 types of ML models?
Binary Classification, Multiclass Classification, and Regression are the three types of main ML models. Binary Classification stands for a model with two outcomes, usually used in decision making. Multiclass Classification is for classifying between different labelled objects. Regression is used for prediction of a future event by employing regressive optimizers.
These three will be the main course of action for us to shape clear dataset creation, automating the creation of machine learning models, and their optimization. Of course a support for fine-tuning hyperparameters for open source deep learning algorithms is another goal. This way we can compare the machine learning models we design with the ones that are designed by large companies, and have a better comparison.
Model Settings
In previous weeks we have implemented a way to automate the configuration of optimizers and criterions from a POST request to an endpoint. The way to automate the algorithm wasn’t implemented. There is a quite useful function of Pytorch that can let us build this.
I have first moved the class responsible for CNN algorithm to a separate file called models.py
This is useful for manual addition in the future.
from commands import TrainCommands, TestCommands
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
import torch
class CNN(nn.Module):
def __init__(self, tc: TrainCommands | TestCommands):
super().__init__()
n_labels = tc.n_labels
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.flatten = nn.Flatten(start_dim=1)
self.fc1 = nn.Linear(16*125*125, 120) # Manually calculated
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, n_labels) #unique label size
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.flatten(x)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Now how can we write all of this, using only limited and ordered variables that won’t disturb the way hyperparameters work? That’s where Sequential function comes in to automate our process:
class CNNSeq(nn.Module):
def __init__(self, tc: TrainCommands | TestCommands):
super(CNNSeq, self).__init__()
n_labels = tc.n_labels
self.layers = nn.Sequential(
# First 2D convolution layer
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Second 2D convolution layer
nn.Conv2d(in_channels= 6, out_channels = 16, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Linear Layers
nn.Flatten(start_dim=1),
nn.Linear(in_features = 16*125*125, out_features = 120),
nn.ReLU(inplace=True),
nn.Linear(in_features = 120, out_features = 84),
nn.ReLU(inplace=True),
nn.Linear(in_features = 84,out_features = n_labels)
)
def forward(self, x):
x = self.layers(x)
return x
As you can see, the hyperparameters are preserved in the machine learning model while the variables are less, and we only use one variable to describe the process. Next step, is to take this, and to make it fully customizable. Let’s initialize it:
class CustomModel(nn.Module):
def __init__(self, tc: TestCommands | TrainCommands):
super(CustomModel, self).__init__()
n_labels = tc.n_labels
layer_commands = tc.model['layers']
layer_list = []
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
The model will be constructed by an array of commands in TestCommands or TrainCommands. This will tell machine learning models how to shape themselves.
There is a requirement for the dataset to be used layer by layer, it has to use proper a certain size after preprocessing. We have reduced the time consuming preprocessing by only getting clear training data as explained in previous weeks. But this requirement is a must in model training. Outlet size of the previous layers in the neural network must be in accordance with the inlet size of the current node in order to do vector calculation. For example, a Convolutional Layer with the outlet 5, must be connected to next Convolutional Layer inlet with 5 again in order for iterative process to be valid. For this kind of scenario, we will use the index of the layer, name of the layer and the layers array to automatically calculate such numbers if we desire to.
def autosize(layer_name, index, layer_commands):
for k in reversed(range(0,len(layer_commands))):
layer = layer_commands[k]
if k < index and layer['name'] == layer_name :
value = [val for key, val in layer.items() if "out" in key][-1]
return value
This function will return the outlet of the last layer with the same kind to be put to use in real-time and automate the layer size.
We will utilize eval function of Python to create the model with the training commands:
for i in range(0, len(layer_commands)):
layer = layer_commands[i]
layer_name = layer['name']
string_operation = "nn.{}(".format(layer_name)
for j in range(1,len(layer.keys())):
key = list(layer.keys())[j]
if layer[key] == "n_labels":
string_operation = string_operation + "{}={},".format(key, n_labels)
elif layer[key] == "auto":
value = autosize(layer_name, i, layer_commands)
string_operation = string_operation + "{}={},".format(key, value)
else:
string_operation = string_operation + "{}={},".format(key, layer[key])
string_operation = string_operation[0:-1] + ").to(device)"
operation = eval(string_operation)
layer_list.append(operation)
self.layers = nn.Sequential(*layer_list).to(device)
This will create the same class we called CNNSeq just before we start the machine learning process.
Finally we call the function responsible for iterative process:
def forward(self, x):
x = self.layers(x)
return x
How do you automate with machine learning?
You can automate with machine learning by training a model that is responsible for automation. Creating machine learning models at scale is a good way to measure the optimization of your model. This way you can compare the results with the traditional methods to get the metrics you want.
For this process, we will use /train and /test endpoints.
If you request the /train endpoint with the following dictionary (optimization is not valid):
{
"model_name": "american_dog_species",
"criterion": {
"name": "CrossEntropyLoss"
},
"optimizer": {
"name": "SGD",
"lr": 0.1,
"momentum": 0.9
},
"batch_size": 4,
"n_epoch": 100,
"n_labels": 0,
"image_ops": [
{
"resize": {
"size": [
500,
500
],
"resample": "Image.ANTIALIAS"
}
},
{
"convert": {
"mode": "'RGB'"
}
}
],
"transform": {
"ToTensor": true,
"Normalize": {
"mean": [
0.5,
0.5,
0.5
],
"std": [
0.5,
0.5,
0.5
]
}
},
"target_transform": {
"ToTensor": true
},
"label_names": [
"American Hairless Terrier imagesize:500x500",
"Alaskan Malamute imagesize:500x500",
"American Eskimo Dog imagesize:500x500",
"Australian Shepherd imagesize:500x500",
"Boston Terrier imagesize:500x500",
"Boykin Spaniel imagesize:500x500",
"Chesapeake Bay Retriever imagesize:500x500",
"Catahoula Leopard Dog imagesize:500x500",
"Toy Fox Terrier imagesize:500x500"
],
"model": {
"name": "",
"layers": [
{
"name": "Conv2d",
"in_channels": 3,
"out_channels": 6,
"kernel_size": 5
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "MaxPool2d",
"kernel_size": 2,
"stride": 2
},
{
"name": "Conv2d",
"in_channels": "auto",
"out_channels": 16,
"kernel_size": 5
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "MaxPool2d",
"kernel_size": 2,
"stride": 2
},
{
"name": "Conv2d",
"in_channels": "auto",
"out_channels": 32,
"kernel_size": 5
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "MaxPool2d",
"kernel_size": 2,
"stride": 2
},
{
"name": "Flatten",
"start_dim": 1
},
{
"name": "Linear",
"in_features": 111392,
"out_features": 120
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "Linear",
"in_features": "auto",
"out_features": 84
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "Linear",
"in_features": "auto",
"out_features": "n_labels"
}
]
}
}
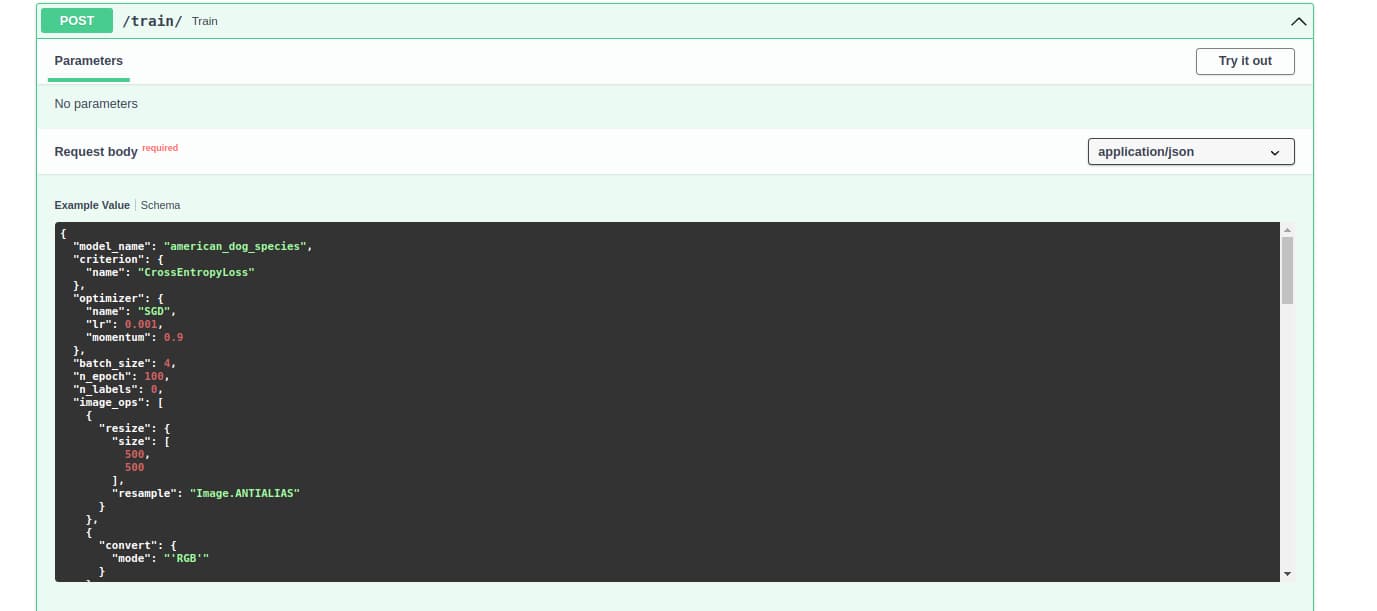
It will create a deep learning model named american_dog_species, with the criterion CrossEntropyLoss, with optimizer SGD, with learning rate, and momentum of the optimizer 0.1, and 0.9 respectively. It will fetch 4 images from the image dataset at each interval, train the algorithms for 100 times with specified image operations, and tensor transformations. It will use the layer dictionary for model building, and label names as the data.
You may notice that the inlet size for linear layer after the last Conv2d layer has not been automatically calculated in the machine learning model. This is something to do in another tutorial in coming weeks.
Now, to test the machine learning model to see if it is able to classify the dataset, we need to send a request to /test endpoint with the following dictionary:
{
"ids": [],
"limit": 200,
"label_names": [
"American Hairless Terrier imagesize:500x500",
"Alaskan Malamute imagesize:500x500",
"American Eskimo Dog imagesize:500x500",
"Australian Shepherd imagesize:500x500",
"Boston Terrier imagesize:500x500",
"Boykin Spaniel imagesize:500x500",
"Chesapeake Bay Retriever imagesize:500x500",
"Catahoula Leopard Dog imagesize:500x500",
"Toy Fox Terrier imagesize:500x500"
],
"n_labels": 0,
"criterion": {
"name": "CrossEntropyLoss"
},
"model_name": "american_dog_species.pt",
"image_ops": [
{
"resize": {
"size": [
500,
500
],
"resample": "Image.ANTIALIAS"
}
},
{
"convert": {
"mode": "'RGB'"
}
}
],
"transform": {
"ToTensor": true,
"Normalize": {
"mean": [
0.5,
0.5,
0.5
],
"std": [
0.5,
0.5,
0.5
]
}
},
"target_transform": {
"ToTensor": true
},
"model": {
"name": "",
"layers": [
{
"name": "Conv2d",
"in_channels": 3,
"out_channels": 6,
"kernel_size": 5
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "MaxPool2d",
"kernel_size": 2,
"stride": 2
},
{
"name": "Conv2d",
"in_channels": "auto",
"out_channels": 16,
"kernel_size": 5
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "MaxPool2d",
"kernel_size": 2,
"stride": 2
},
{
"name": "Conv2d",
"in_channels": "auto",
"out_channels": 32,
"kernel_size": 5
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "MaxPool2d",
"kernel_size": 2,
"stride": 2
},
{
"name": "Flatten",
"start_dim": 1
},
{
"name": "Linear",
"in_features": 111392,
"out_features": 120
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "Linear",
"in_features": "auto",
"out_features": 84
},
{
"name": "ReLU",
"inplace": true
},
{
"name": "Linear",
"in_features": "auto",
"out_features": "n_labels"
}
]
}
}
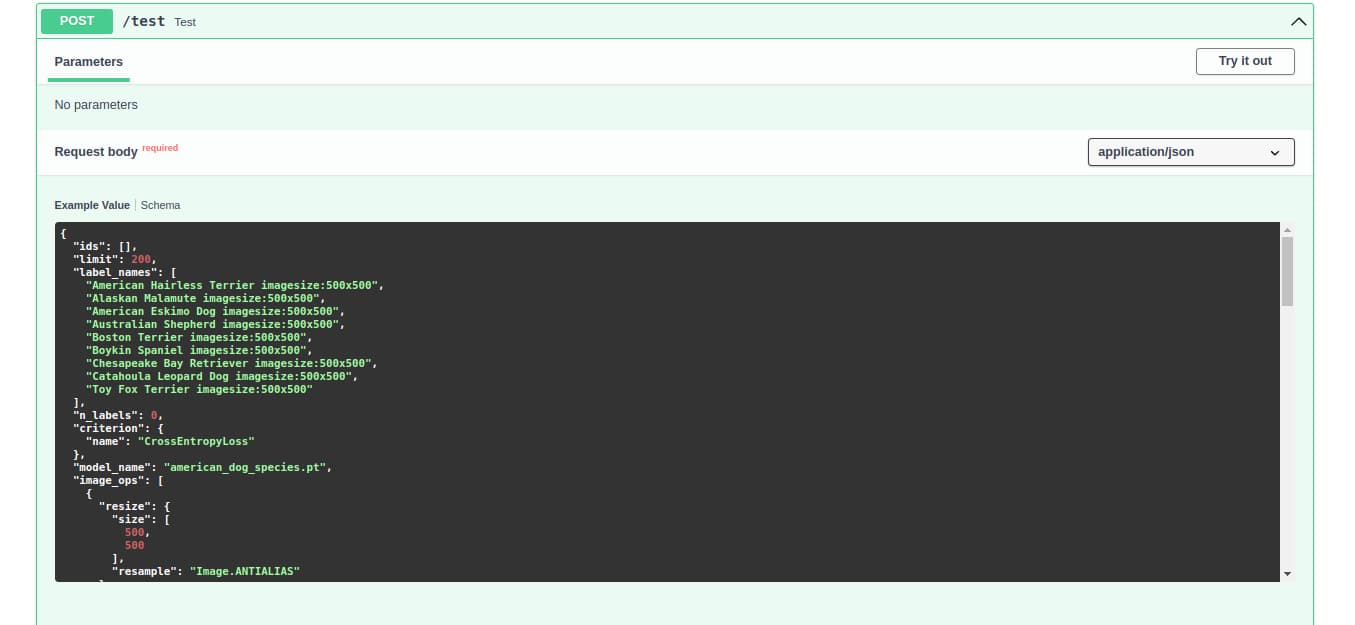
This will create the same machine learning algorithm we trained in order to give us a validation result. As I mentioned before, I didn’t do any optimization on the hyperparameters, so the validation results will not have any use case for us.
Finally let’s improve the endpoints to get a deep learning model by its class name, or its layer dictionary:
@app.post("/train/")
def train(tc: TrainCommands):
if tc.model['name'] != None and tc.model['name'] != "":
model = eval(tc.model['name'])
else:
model = CustomModel
trainer = Train(tc, model, CustomImageDataLoader, CustomImageDataset, ImagesDataBase)
trainer.train()
model = None
try:
torch.cuda.empty_cache()
except:
pass
return {"status": "Success"}
@app.post("/test")
def test(tc: TestCommands):
if tc.model['name'] != None and tc.model['name'] != "":
model = eval(tc.model['name'])
else:
model = CustomModel
tester = Test(tc, CustomImageDataset, ImagesDataBase, model)
accuracy = tester.test_accuracy()
model = None
try:
torch.cuda.empty_cache()
except:
pass
return {"status": "Success","accuracy": "{}".format(accuracy)}
We also remove the model in the GPU to save some time in between each machine learning process. Also you may add a model manually inside models.py, and call it by its name by omitting the layers dictionary in automated machine learning process.
You may observe that instead of going back and forth with Python code, trying to optimize the machine learning model, you may easily customize the number of layers, hyperparameters, model selection, and get the result on the model performance. This is especially good practice for general mlops. It could reduce the time necessary for neural architecture search, data preparation, usage of new data, and model development, hyperparameter optimization without giving any kind of concession. Also you may easily scale up or down feature selection without creating time consuming a busy workflow.
Conclusion
I am grateful to the readers for their attention, and Brilliant People of SerpApi for making these series possible. In the following weeks, we will take a look at visualizing training process data on frontend, add missing parts such as ability to support transfer learning, and to interpret time series. We will also discuss possible feature engineering and meta learning angles for deep neural networks that can open up the way for artificial intelligence with more real-world use cases. We will also discuss how to implement support for other libraries such as tensorflow, powerful scikit-learn (a.k.a. sklearn), ability to be integrated with cloud services such as Microsoft Azure. We will also automate some machine learning models to solve small scale real-world problems in healthcare.




