

Table of contents
What will be scraped

Prerequisites
Basic knowledge scraping with CSS selectors
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective and show the most common approaches of using CSS selectors when web scraping.
Separate virtual environment
If you didn't work with a virtual environment before, have a look at the dedicated Python virtual environments tutorial using Virtualenv and Poetry blog post of mine to get familiar.
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites.
📌Note: if you'll be using this code snippet without proxies, the requests will be blocked in a short period of time. Scraping with proxies large amount of data is a way to go.
Install libraries:
pip install parsel playwright
Full Code
from parsel import Selector
from playwright.sync_api import sync_playwright
import json
def scrape_researchgate_profile(query: str):
with sync_playwright() as p:
browser = p.chromium.launch(headless=True, slow_mo=50)
page = browser.new_page(user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36")
authors = []
page_num = 1
while True:
page.goto(f"https://www.researchgate.net/search/researcher?q={query}&page={page_num}")
selector = Selector(text=page.content())
for author in selector.css(".nova-legacy-c-card__body--spacing-inherit"):
name = author.css(".nova-legacy-v-person-item__title a::text").get()
thumbnail = author.css(".nova-legacy-v-person-item__image img::attr(src)").get()
profile_page = f'https://www.researchgate.net/{author.css("a.nova-legacy-c-button::attr(href)").get()}'
institution = author.css(".nova-legacy-v-person-item__stack-item:nth-child(3) span::text").get()
department = author.css(".nova-legacy-v-person-item__stack-item:nth-child(4) span").xpath("normalize-space()").get()
skills = author.css(".nova-legacy-v-person-item__stack-item:nth-child(5) span").xpath("normalize-space()").getall()
last_publication = author.css(".nova-legacy-v-person-item__info-section-list-item .nova-legacy-e-link--theme-bare::text").get()
last_publication_link = f'https://www.researchgate.net{author.css(".nova-legacy-v-person-item__info-section-list-item .nova-legacy-e-link--theme-bare::attr(href)").get()}'
authors.append({
"name": name,
"profile_page": profile_page,
"institution": institution,
"department": department,
"thumbnail": thumbnail,
"last_publication": {
"title": last_publication,
"link": last_publication_link
},
"skills": skills,
})
print(f"Extracting Page: {page_num}")
# checks if next page arrow key is greyed out `attr(rel)` (inactive) -> breaks out of the loop
if selector.css(".nova-legacy-c-button-group__item:nth-child(9) a::attr(rel)").get():
break
else:
# paginate to the next page
page_num += 1
print(json.dumps(authors, indent=2, ensure_ascii=False))
browser.close()
scrape_researchgate_profile(query="coffee")
Code explanation
Import libraries:
from parsel import Selector
from playwright.sync_api import sync_playwright
import json
| Code | Explanation |
parsel | to parse HTML/XML documents. Supports XPath. |
playwright | to render the page with a browser instance. |
json | to convert Python dictionary to JSON string. |
Define a function and open a playwright with a context manager::
def scrape_researchgate_profile(query: str):
with sync_playwright() as p:
# ...
| Code | Explanation |
query: str | to tell Python that query should be an str. |
Lunch a browser instance, open new_page with passed user-agent:
browser = p.chromium.launch(headless=True, slow_mo=50)
page = browser.new_page(user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36")
| Code | Explanation |
p.chromium.launch() | to launch Chromium browser instance. |
headless | to explicitly tell playwright to run in headless mode even though it's a defaut value. |
slow_mo | to tell playwright to slow down execution. |
browser.new_page() | to open new page. user_agent is used to act a real user makes a request from the browser. If not used, it will default to playwright value which is None. Check what's your user-agent. |
Add a temporary list, set up a while loop, and open a new URL:
authors = []
while True:
page.goto(f"https://www.researchgate.net/search/researcher?q={query}&page={page_num}")
selector = Selector(text=page.content())
# ...
| Code | Explanation |
goto() | to make a request to specific URL with passed query and page parameters. |
Selector() | to pass returned HTML data with page.content() and process it. |
Iterate over author results on each page, extract the data and append to a temporary list:
for author in selector.css(".nova-legacy-c-card__body--spacing-inherit"):
name = author.css(".nova-legacy-v-person-item__title a::text").get()
thumbnail = author.css(".nova-legacy-v-person-item__image img::attr(src)").get()
profile_page = f'https://www.researchgate.net/{author.css("a.nova-legacy-c-button::attr(href)").get()}'
institution = author.css(".nova-legacy-v-person-item__stack-item:nth-child(3) span::text").get()
department = author.css(".nova-legacy-v-person-item__stack-item:nth-child(4) span").xpath("normalize-space()").get()
skills = author.css(".nova-legacy-v-person-item__stack-item:nth-child(5) span").xpath("normalize-space()").getall()
last_publication = author.css(".nova-legacy-v-person-item__info-section-list-item .nova-legacy-e-link--theme-bare::text").get()
last_publication_link = f'https://www.researchgate.net{author.css(".nova-legacy-v-person-item__info-section-list-item .nova-legacy-e-link--theme-bare::attr(href)").get()}'
authors.append({
"name": name,
"profile_page": profile_page,
"institution": institution,
"department": department,
"thumbnail": thumbnail,
"last_publication": {
"title": last_publication,
"link": last_publication_link
},
"skills": skills,
})
| Code | Explanation |
css() | to parse data from the passed CSS selector(s). Every CSS query traslates to XPath using csselect package under the hood. |
::text/::attr(attribute) | to extract textual or attribute data from the node. |
get()/getall() | to get actual data from a matched node, or to get a list of matched data from nodes. |
xpath("normalize-space()") | to parse blank text node as well. By default, blank text node is be skipped by XPath. |
Check if the next page is present and paginate:
# checks if the next page arrow key is greyed out `attr(rel)` (inactive) -> breaks out of the loop
if selector.css(".nova-legacy-c-button-group__item:nth-child(9) a::attr(rel)").get():
break
else:
page_num += 1
Print extracted data, and close browser instance:
print(json.dumps(authors, indent=2, ensure_ascii=False))
browser.close()
# call the function
scrape_researchgate_profile(query="coffee")
Part of the JSON output:
[
{
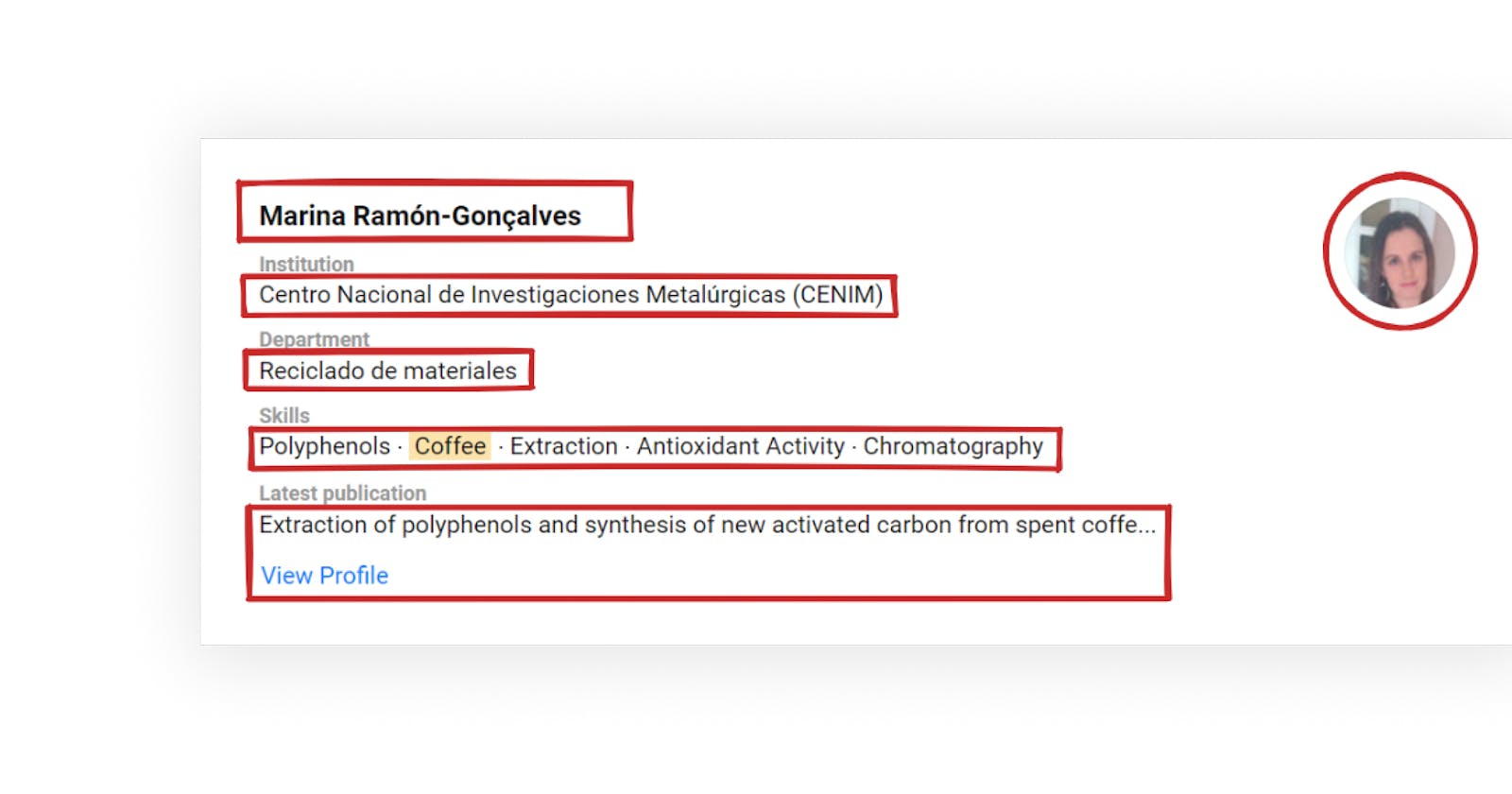
"name": "Marina Ramón-Gonçalves", # first profile
"profile_page": "https://www.researchgate.net/profile/Marina-Ramon-Goncalves?_sg=VbWMth8Ia1hDG-6tFnNUWm4c8t6xlBHy2Ac-2PdZeBK6CS3nym5PM5OeoSzha90f2B6hpuoyBMwm24U",
"institution": "Centro Nacional de Investigaciones Metalúrgicas (CENIM)",
"department": "Reciclado de materiales",
"thumbnail": "https://i1.rgstatic.net/ii/profile.image/845010970898442-1578477723875_Q64/Marina-Ramon-Goncalves.jpg",
"last_publication": {
"title": "Extraction of polyphenols and synthesis of new activated carbon from spent coffe...",
"link": "https://www.researchgate.netpublication/337577823_Extraction_of_polyphenols_and_synthesis_of_new_activated_carbon_from_spent_coffee_grounds?_sg=2y4OuZz32W46AWcUGmwYbW05QFj3zkS1QR_MVxvKwqJG-abFPLF6cIuaJAO_Mn5juJZWkfEgdBwnA5Q"
},
"skills": [
"Polyphenols",
"Coffee",
"Extraction",
"Antioxidant Activity",
"Chromatography"
]
}, ... other profiles
{
"name": "Kingsten Okka", # last profile
"profile_page": "https://www.researchgate.net/profile/Kingsten-Okka?_sg=l1w_rzLrAUCRFtoo3Nh2-ZDAaG2t0NX5IHiSV5TF2eOsDdlP8oSuHnGglAm5tU6OFME9wgfyAd-Rnhs",
"institution": "University of Southern Queensland ",
"department": "School of Agricultural, Computational and Environmental Sciences",
"thumbnail": "https://i1.rgstatic.net/ii/profile.image/584138105032704-1516280785714_Q64/Kingsten-Okka.jpg",
"last_publication": {
"title": null,
"link": "https://www.researchgate.netNone"
},
"skills": [
"Agricultural Entomology",
"Coffee"
]
}
]
Links
Add a Feature Request💫 or a Bug🐞