

Intro
Async requests are necessary when you need to get a lot of data quickly or not in real time.
This blog post is about:
- How to make async request with SerpApi.
- Understand
asyncparameter. - What is
Queueand how to use use. - Search Archive API and how to retrieve data.
The subject of test: YouTube Search Engine Results API.
The test includes: 500 YouTube search requests, and extraction of the data.
What is Async parameter
We have a async parameter that tells SerpApi not to wait for the search to be completed thus allows to send more requests faster. The search will be sent and processed on the SerpApi backend.
After all requests have been sent, the data will be extracted from the Search Archive API and checked if the search succeeded or not.
📌Note: This blog post does not cover multithreading.
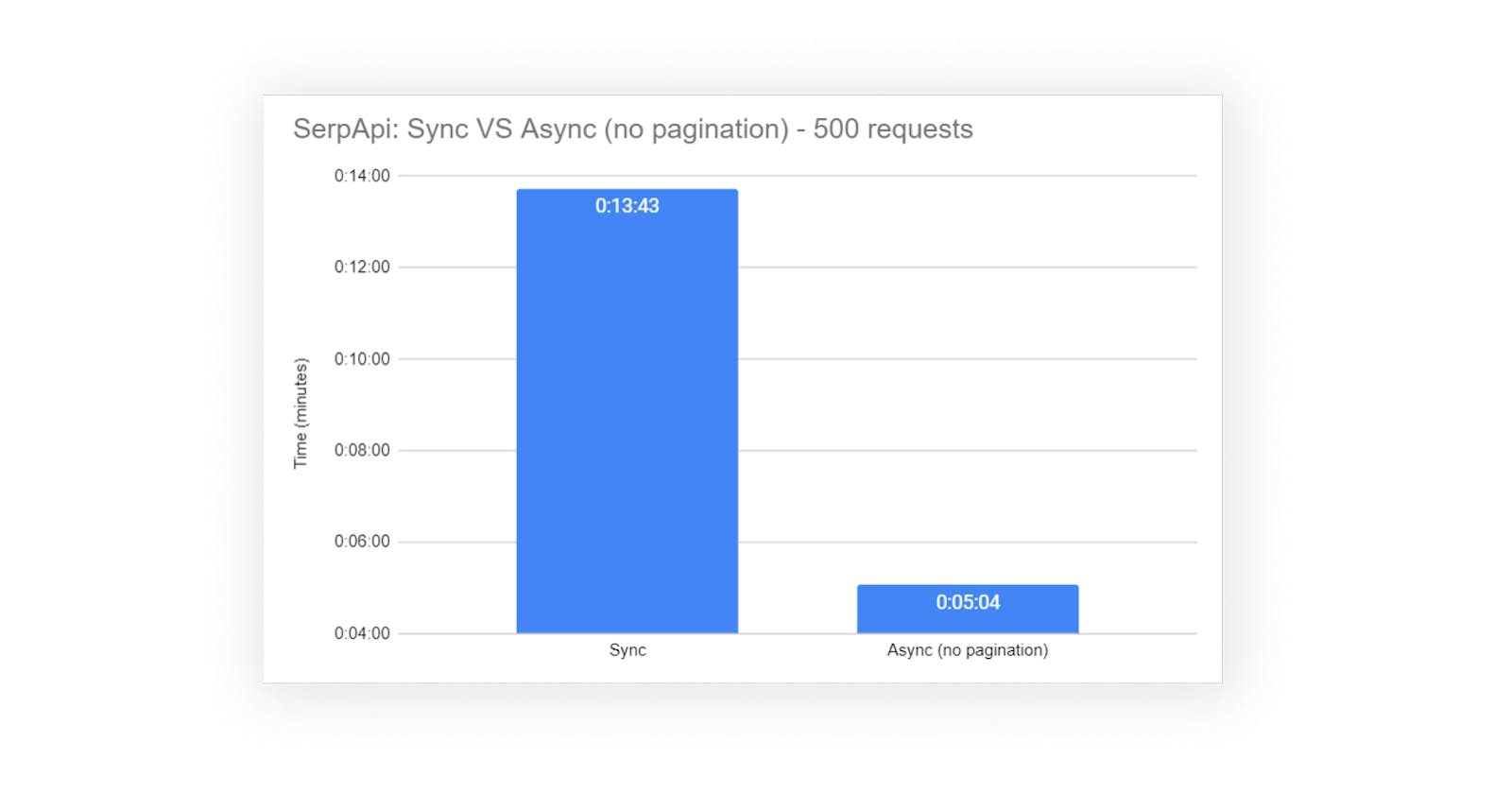
Time Comparison
Time was recorded using $ time python <file.py>:
| Type | Sync requests | Async requests (no pagination) | % difference |
| real | 13m 43.311s | 5m 3.663s | +36.88% increase |
| user | 0m 5.942s | 0m 11.222s | -52.95% decrease |
| sys | 0m 0.813s | 0m 1.191s | -68.26% decrease |

SerpApi Sync Requests
from serpapi import YoutubeSearch
import os, re, json
# shortened for the sake of not making code very long
queries = [
'burly',
'silk',
'monkey',
'abortive',
'hot'
]
data = []
for query in queries:
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'youtube', # search engine
'device': 'desktop', # device type
'search_query': query, # search query
}
search = YoutubeSearch(params) # where data extraction happens
results = search.get_dict() # JSON -> Python dict
if 'error' in results:
print(results['error'])
break
for result in results.get('video_results', []):
data.append({
'title': result.get('title'),
'link': result.get('link'),
'channel': result.get('channel').get('name'),
})
print(json.dumps(data, indent=2, ensure_ascii=False))
Sync Code Explanation
Import libraries:
from serpapi import YoutubeSearch
import os, re, json
Create a list of search queries you want to search:
queries = [
'burly',
'silk',
'monkey',
'abortive',
'hot'
]
Create a temporary list that will store extracted data:
data = []
Add a for loop to iterate over all queries, create SerpApi YouTube search parameters, and pass them YoutubeSearch which will make a request to SerpApi:
for query in queries:
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'youtube', # search engine
'device': 'desktop', # device type
'search_query': query, # search query
}
search = YoutubeSearch(params) # where data extraction happens
results = search.get_dict() # JSON -> Python dict
Check for 'errors', iterate over video results and extract needed data to the temporary list, and print it:
if 'error' in results:
print(results['error'])
break
for result in results.get('video_results', []):
data.append({
'title': result.get('title'),
'link': result.get('link'),
'channel': result.get('channel').get('name'),
})
print(json.dumps(data, indent=2, ensure_ascii=False))
SerpApi Async Batch Requests without Pagination
from serpapi import YoutubeSearch
from urllib.parse import (parse_qsl, urlsplit)
from queue import Queue
import os, re, json
queries = [
'burly',
'silk',
'monkey',
'abortive',
'hot'
]
search_queue = Queue()
for query in queries:
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'youtube', # search engine
'device': 'desktop', # device type
'search_query': query, # search query
'async': True, # async batch requests
}
search = YoutubeSearch(params) # where data extraction happens
results = search.get_dict() # JSON -> Python dict
if 'error' in results:
print(results['error'])
break
print(f"add search to the queue with ID: {results['search_metadata']}")
search_queue.put(results)
data = []
while not search_queue.empty():
result = search_queue.get()
search_id = result['search_metadata']['id']
print(f'Get search from archive: {search_id}')
search_archived = search.get_search_archive(search_id)
print(f"Search ID: {search_id}, Status: {search_archived['search_metadata']['status']}")
if re.search(r'Cached|Success', search_archived['search_metadata']['status']):
for result in search_archived.get('video_results', []):
data.append({
'title': result.get('title'),
'link': result.get('link'),
'channel': result.get('channel').get('name'),
})
else:
print(f'Requeue search: {search_id}')
search_queue.put(result)
print(json.dumps(data, indent=2))
print('all searches completed')
Async Batch Requests without Pagination Explanation
Same as before, import libraries (a few more):
from serpapi import YoutubeSearch
from urllib.parse import (parse_qsl, urlsplit)
from queue import Queue
import os, re, json
Create a list of search queries you want to search:
queries = [
'burly',
'silk',
'monkey',
'abortive',
'hot'
]
Create a Queue to store all the requests that have been sent to SerpApi:
search_queue = Queue()
Iterate over all queries, create SerpApi YouTube search parameters with 'async': True parameter present. Check for errors and put() search in the queue:
for query in queries:
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'youtube', # search engine
'device': 'desktop', # device type
'search_query': query, # search query
'async': True, # async batch requests
}
search = YoutubeSearch(params) # where data extraction happens
results = search.get_dict() # JSON -> Python dict
if 'error' in results:
print(results['error'])
break
print(f"add search to the queue with ID: {results['search_metadata']}")
search_queue.put(results)
Create a temporary list that will be used to store extracted data from the search archive API:
data = []
Iterate over all queue until it's empty() and get the data from search archive by accessing search ID:
while not search_queue.empty():
result = search_queue.get()
search_id = result['search_metadata']['id']
print(f'Get search from archive: {search_id}')
search_archived = search.get_search_archive(search_id)
print(f"Search ID: {search_id}, Status: {search_archived['search_metadata']['status']}")
Check if the search is either cached or succeeded, if so, extract needed data, otherwise we need to requeue the result:
if re.search(r'Cached|Success', search_archived['search_metadata']['status']):
for result in search_archived.get('video_results', []):
data.append({
'title': result.get('title'),
'link': result.get('link'),
'channel': result.get('channel').get('name'),
})
else:
print(f'Requeue search: {search_id}')
search_queue.put(result)
print(json.dumps(data, indent=2))
print('all searches completed')
That's basically it 🙂
To sum-up:
- Send all the requests and store them in the queue.
- When all requests have been sent, grab them one by one from the queue until the queue is empty.
- Extract search ID. The search ID will not be random, it will be the right one from the queue it was earlier stored.
- Check if the search is succeeded and extract the data. If not, requeue it.
What comes next
In the next blog post that will be specifically about Async requests using SerpApi, we'll cover the following:
- how to speed up async requests i.e. multithreading
Queue. - how to add pagination with
asyncparameter.