


Intro
This is a part of the series of blog posts related to Artificial Intelligence Implementation. If you are interested in the background of the story or how it goes:
This week we'll showcase testing process and the early results of the model. We will be using SerpApi's Google Organic Results Scraper API for the data collection. Also, you can check in the playground in more detailed view on the data we will use.
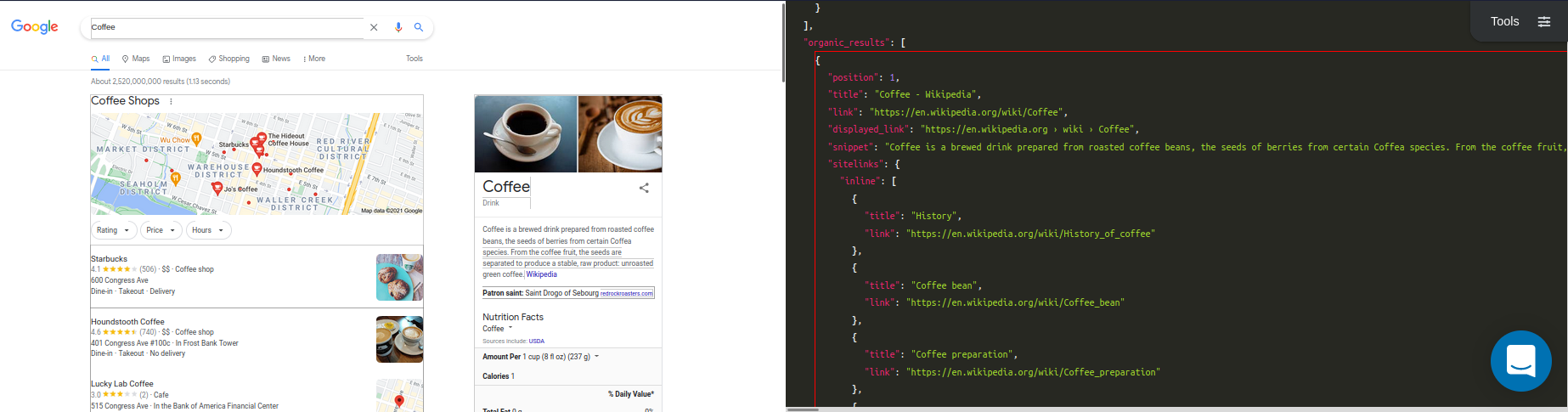
Training Data
Here's an structural breakdown of the data we store for training inside a json file:
[
{
"Key 1": Value_1,
"Key 2": Value_2,
"Key 3": Value_3,
"Key 4": [
"Value_1",
...
],
"Key 5": {
"Inner Key 1": Inner_Value_1,
...
},
...
]
Here's an example:
[
{
"position": 1,
"title": "Coffee - Wikipedia",
"link": "https://en.wikipedia.org/wiki/Coffee",
"displayed_link": "https://en.wikipedia.org › wiki › Coffee",
"snippet": "Coffee is a brewed drink prepared from roasted coffee beans, the seeds of berries from certain flowering plants in the Coffea genus. From the coffee fruit, ...",
"snippet_highlighted_words": [
"Coffee",
"coffee",
"coffee"
],
...
},
...
]
Links we collected the organic results of Google from: Link for Tea (around 100 results) Link for Coffee (around 100 results)
Testing Structure
We have already covered how we trained the data in detail in the past three week's blog posts. Today, we will test how the hypothesis holds by calculating the training accuracy.
We can reutilize the Train, and Database classes to create examples, and create example vectors with the following lines:
example_vector = Database.word_to_tensor example
example_vector.map! {|el| el = el.nil? ? 0: el}
example_vector = Train.extend_vector example_vector
weighted_example = Train.product example_vector
,
example in here is the string we provide. Any value for any key within Google Organic Results that is converted to a string will be a valid example.
We can reutilize Database.word_to_tensor to get the vectorized version of our string in accordance with our vocabulary.
If any value is nil (null), which is not present in our vocabulary, it will be replaced with 0, which is the value for our <unk> (unknown).
example_vector, then, should be expanded to maximum string size for calculation purposes using 1s.
weighted_example will be the product of the @@weights we calculated earlier with our vectorized example.
This value's closest vectors in multidimensional space, from the examples we provided, should have the same key, or their average should lead us to the same key. So, in our case, if the example we provide isn't a snippet, closest vectors around the weighted_example should give us less than 0.5 (their identities are 0 and 1) in average. Conclusion should be that the example isn't a snippet.
We measure the distance of our example with every example in the dataset using Euclidean Distance formula for multidimensional space:
distances = []
vector_array.each_with_index do |comparison_vector, vector_index|
distances << Train.euclidean_distance(comparison_vector, weighted_example)
end
We take the indexes of the minimum distances (k many times):
indexes = []
k.times do
index = distances.index(distances.min)
indexes << index
distances[index] = 1000000000
end
Then, we take the real identities of each of these vectors:
predictions = []
indexes.each do |index|
predictions << key_array[index].first.to_i
end
key_array here is the array containing 0, or 1 in first item of each row, and the string in second. To give an example:
[
...
["0", "https://www.coffeebean.com"],
["1", "Born and brewed in Southern California since 1963, The Coffee Bean & Tea Leaf® is passionate about connecting loyal customers with carefully handcrafted ..."],
["0", "4"],
...
]
1 represents that the item is snippet, 0 represents it isn't.
Let's return the predictions:
prediction = (predictions.sum/predictions.size).to_f
if prediction < 0.5
puts "False - Item is not Snippet"
return 0
else
puts "True - Item is Snippet"
return 1
end
Here's the full method for it:
def test example, k, vector_array, key_array
example_vector = Database.word_to_tensor example
example_vector.map! {|el| el = el.nil? ? 0: el}
example_vector = Train.extend_vector example_vector
weighted_example = Train.product example_vector
distances = []
vector_array.each_with_index do |comparison_vector, vector_index|
distances << Train.euclidean_distance(comparison_vector, weighted_example)
end
indexes = []
k.times do
index = distances.index(distances.min)
indexes << index
distances[index] = 1000000000
end
predictions = []
indexes.each do |index|
predictions << key_array[index].first.to_i
end
puts "Predictions: #{predictions}"
prediction = (predictions.sum/predictions.size).to_f
if prediction < 0.5
puts "False - Item is not Snippet"
return 0
else
puts "True - Item is Snippet"
return 1
end
end
Testing with Google Organic Results for Snippet
Now that we have a function for testing, let's separate snippets from non-snippets in our examples:
true_examples = key_array.map {|el| el = el.first == "1" ? el.second : nil}.compact
false_examples = key_array.map {|el| el = el.first == "0" ? el.second : nil}.compact
This will allow us to calculate easier.
Let's declare an empty array to collect predictions, and start with non-snippets:
predictions = []
false_examples.each do |example|
prediction = test example, 2, vector_array, key_array
predictions << prediction
end
predictions.map! {|el| el = el == 1 ? 0 : 1}
Since we know that none of these examples are snippet, any prediction that gives 1 will be wrong. So if we test our model with false examples, and then reverse 1s to 0s, and 0s to 1s, we can combine it with our true examples:
true_examples.each do |example|
prediction = test example, 2, vector_array, key_array
predictions << prediction
end
Now that we have the desired array filled:
prediction_train_accuracy = predictions.sum.to_f / predictions.size.to_f
puts "Prediction Accuracy for Training Set is: #{prediction_train_accuracy}"
If we divide the number of 1s to number of predictions, we can calculate the accuracy results.
Preliminary Results
We have done exactly the same process for the data we mentioned earlier. The number of predictions for snippet was 1065, and the k value was 2, and the n-gram value was 2.
The model predicted 872 times correctly. This means the training accuracy was 0.8187793427230047 (%81.87).
This is a good number to start, and with more tweaks, and testing with a bigger dataset, the initial hypothesis could be proven to be true.
Full Code
class Database
def initialize json_data, vocab = { "<unk>" => 0, "<pad>" => 1 }
super()
@@pattern_data = []
@@vocab = vocab
end
## Related to creating main database
def self.add_new_data_to_database json_data, csv_path = nil
json_data.each do |result|
recursive_hash_pattern result, ""
end
@@pattern_data = @@pattern_data.reject { |pattern| pattern.include? nil }.uniq.compact
path = "#{csv_path}master_database.csv"
File.write(path, @@pattern_data.map(&:to_csv).join)
end
def self.element_pattern result, pattern
@@pattern_data.append([result, pattern].flatten)
end
def self.element_array_pattern result, pattern
result.each do |element|
element_pattern element, pattern
end
end
def self.assign hash, key, pattern
if hash[key].is_a?(Hash)
if pattern.present?
pattern = "#{pattern}__#{key}"
else
pattern = "#{key}"
end
recursive_hash_pattern hash[key], pattern
elsif hash[key].present? && hash[key].is_a?(Array) && hash[key].first.is_a?(Hash)
if pattern.present?
pattern = "#{pattern}__#{key}__n"
else
pattern = "#{key}"
end
hash[key].each do |hash_inside_array|
recursive_hash_pattern hash_inside_array, pattern
end
elsif hash[key].present? && hash[key].is_a?(Array)
if pattern.present?
pattern = "#{pattern}__n"
else
pattern = "#{key}"
end
element_array_pattern hash[key], pattern
else
if pattern.present?
pattern = "#{pattern}__#{key}"
else
pattern = "#{key}"
end
element_pattern hash[key], pattern
end
end
def self.recursive_hash_pattern hash, pattern
hash.keys.each do |key|
assign hash, key, pattern
end
end
## Related to tokenizing
def self.default_dictionary_hash
{
/\"/ => "",
/\'/ => " \' ",
/\./ => " . ",
/,/ => ", ",
/\!/ => " ! ",
/\?/ => " ? ",
/\;/ => " ",
/\:/ => " ",
/\(/ => " ( ",
/\)/ => " ) ",
/\// => " / ",
/\s+/ => " ",
/<br \/>/ => " , ",
/http/ => "http",
/https/ => " https ",
}
end
def self.tokenizer word, dictionary_hash = default_dictionary_hash
word = word.downcase
dictionary_hash.keys.each do |key|
word.sub!(key, dictionary_hash[key])
end
word.split
end
def self.iterate_ngrams token_list, ngrams = 2
token_list.each do |token|
1.upto(ngrams) do |n|
permutations = (token_list.size - n + 1).times.map { |i| token_list[i...(i + n)] }
permutations.each do |perm|
key = perm.join(" ")
unless @@vocab.keys.include? key
@@vocab[key] = @@vocab.size
end
end
end
end
end
def self.word_to_tensor word
token_list = tokenizer word
token_list.map {|token| @@vocab[token]}
end
## Related to creating key-specific databases
def self.create_key_specific_databases result_type = "organic_results", csv_path = nil, dictionary = nil, ngrams = nil, vocab_path = nil
keys, examples = create_keys_and_examples
keys.each do |key|
specific_pattern_data = []
@@pattern_data.each_with_index do |pattern, index|
word = pattern.first.to_s
next if word.blank?
if dictionary.present?
token_list = tokenizer word, dictionary
else
token_list = tokenizer word
end
if ngrams.present?
iterate_ngrams token_list, ngrams
else
iterate_ngrams token_list
end
if key == pattern.second
specific_pattern_data << [ 1, word ]
elsif (examples[key].to_s.to_i == examples[key]) && word.to_i == word
next
elsif (examples[key].to_s.to_i == examples[key]) && word.numeric?
specific_pattern_data << [ 0, word ]
elsif examples[key].numeric? && word.numeric?
next
elsif key.split("__").last == pattern.second.to_s.split("__").last
specific_pattern_data << [ 1, word ]
else
specific_pattern_data << [ 0, word ]
end
end
path = "#{csv_path}#{result_type}__#{key}.csv"
File.write(path, specific_pattern_data.map(&:to_csv).join)
end
if vocab_path.present?
save_vocab vocab_path
else
save_vocab
end
end
def self.create_keys_and_examples
keys = @@pattern_data.map { |pattern| pattern.second }.uniq
examples = {}
keys.each do |key|
examples[key] = @@pattern_data.find { |pattern| pattern.first.to_s if pattern.second == key }
end
[keys, examples]
end
def self.numeric?
return true if self =~ /\A\d+\Z/
true if Float(self) rescue false
end
def self.save_vocab vocab_path = ""
path = "#{vocab_path}vocab.json"
vocab = JSON.parse(@@vocab.to_json)
File.write(path, JSON.pretty_generate(vocab))
end
def self.read_vocab vocab_path
vocab = File.read vocab_path
@@vocab = JSON.parse(vocab)
end
def self.return_vocab
@@vocab
end
end
class Train
def initialize csv_path
@@csv_path = csv_path
@@vector_arr = []
@@word_arr = []
@@maximum_word_size = 100
@@weights = Vector[]
@@losses = []
end
def self.read
@@word_arr = CSV.read(@@csv_path)
@@word_arr
end
def self.define_training_set vectors
@@vector_arr = vectors
end
def self.auto_define_maximum_size
@@maximum_word_size = @@vector_arr.map {|el| el.size}.max
end
def self.extend_vector vector
vector_arr = vector.to_a
(@@maximum_word_size - vector.size).times { vector_arr << 1 }
Vector.[](*vector_arr)
end
def self.extend_vectors
@@vector_arr.each_with_index do |vector, index|
@@vector_arr[index] = extend_vector vector
end
end
def self.initialize_weights
weights = []
@@maximum_word_size.times { weights << 1.0 }
@@weights = Vector.[](*weights)
end
def self.config k = 1, lr = 0.001
[k, lr]
end
def self.product vector
@@weights.each_with_index do |weight, index|
vector[index] = weight * vector[index]
end
vector
end
def self.euclidean_distance vector_1, vector_2
subtractions = (vector_1 - vector_2).to_a
subtractions.map! {|sub| sub = sub*sub }
Math.sqrt(subtractions.sum)
end
def self.k_neighbors distances, k
indexes = []
(k).times do
min = distances.index(distances.min)
indexes << min
distances[min] = distances.max + 1
end
indexes
end
def self.make_prediction indexes
predictions = []
indexes.each do |index|
predictions << @@word_arr[index][0].to_i
end
predictions.sum/predictions.size
end
def self.update_weights result, indexes, vector, lr
indexes.each do |index|
subtractions = @@vector_arr[index] - vector
subtractions.each_with_index do |sub, sub_index|
if result == 0 && sub >= 0
@@weights[sub_index] = @@weights[sub_index] + lr
elsif result == 0 && sub < 0
@@weights[sub_index] = @@weights[sub_index] - lr
elsif result == 1 && sub >= 0
@@weights[sub_index] = @@weights[sub_index] - lr
elsif result == 1 && sub < 0
@@weights[sub_index] = @@weights[sub_index] + lr
end
end
end
end
def self.mean_absolute_error real, indexes
errors = []
indexes.each do |index|
errors << (@@word_arr[index][0].to_i - real).abs
end
(errors.sum/errors.size).to_f
end
def self.train vector, index
k, lr = config
vector = extend_vector vector
vector = product vector
distances = []
@@vector_arr.each_with_index do |comparison_vector, vector_index|
if vector_index == index
distances << 100000000
else
distances << euclidean_distance(comparison_vector, vector)
end
end
indexes = k_neighbors distances, k
real = @@word_arr[index][0].to_i
prob_prediction = make_prediction indexes
prediction = prob_prediction > 0.5 ? 1 : 0
result = real == prediction ? 1 : 0
update_weights result, indexes, vector, lr
loss = mean_absolute_error real, indexes
@@losses << loss
puts "Result : #{real}, Prediction: #{prediction}"
puts "Loss: #{loss}"
prediction
end
end
json_path = "organic_results/example.json"
json_data = File.read(json_path)
json_data = JSON.parse(json_data)
Database.new json_data
## For training from scratch
Database.add_new_data_to_database json_data, csv_path = "organic_results/"
Database.create_key_specific_databases result_type = "organic_results", csv_path = "organic_results/"
##
Database.read_vocab "vocab.json"
## We will use an iteration of csvs within a specific path in the end
csv_path = "organic_results/organic_results__snippet.csv"
Train.new csv_path
key_array = Train.read
vector_array = key_array.map { |word| Database.word_to_tensor word[1] }
Train.define_training_set vector_array
Train.auto_define_maximum_size
Train.extend_vectors
Train.initialize_weights
Train.config k = 2
vector_array.each_with_index do |vector, index|
Train.train vector, index
end
def test example, k, vector_array, key_array
example_vector = Database.word_to_tensor example
example_vector.map! {|el| el = el.nil? ? 0: el}
example_vector = Train.extend_vector example_vector
weighted_example = Train.product example_vector
distances = []
vector_array.each_with_index do |comparison_vector, vector_index|
distances << Train.euclidean_distance(comparison_vector, weighted_example)
end
indexes = []
k.times do
index = distances.index(distances.min)
indexes << index
distances[index] = 1000000000
end
predictions = []
indexes.each do |index|
predictions << key_array[index].first.to_i
end
puts "Predictions: #{predictions}"
prediction = (predictions.sum/predictions.size).to_f
if prediction < 0.5
puts "False - Item is not Snippet"
return 0
else
puts "True - Item is Snippet"
return 1
end
end
true_examples = key_array.map {|el| el = el.first == "1" ? el.second : nil}.compact
false_examples = key_array.map {|el| el = el.first == "0" ? el.second : nil}.compact
predictions = []
false_examples.each do |example|
prediction = test example, 2, vector_array, key_array
predictions << prediction
end
predictions.map! {|el| el = el == 1 ? 0 : 1}
true_examples.each do |example|
prediction = test example, 2, vector_array, key_array
predictions << prediction
end
prediction_train_accuracy = predictions.sum.to_f / predictions.size.to_f
puts "Prediction Accuracy for Training Set is: #{prediction_train_accuracy}"
Conclusion
I'd like to apologize the reader for being one day late on the blog post. Two weeks later, we will showcase how to store them for implementation, and further tweaks to improve accuracy.
The end aim of this project is to create an open-source gem to be implemented by everyone using a JSON Data Structure in their code.
I'd like to thank the reader for their attention, and the brilliant people of SerpApi creating wonders even in times of hardship, and for all their support.