

Table of contents
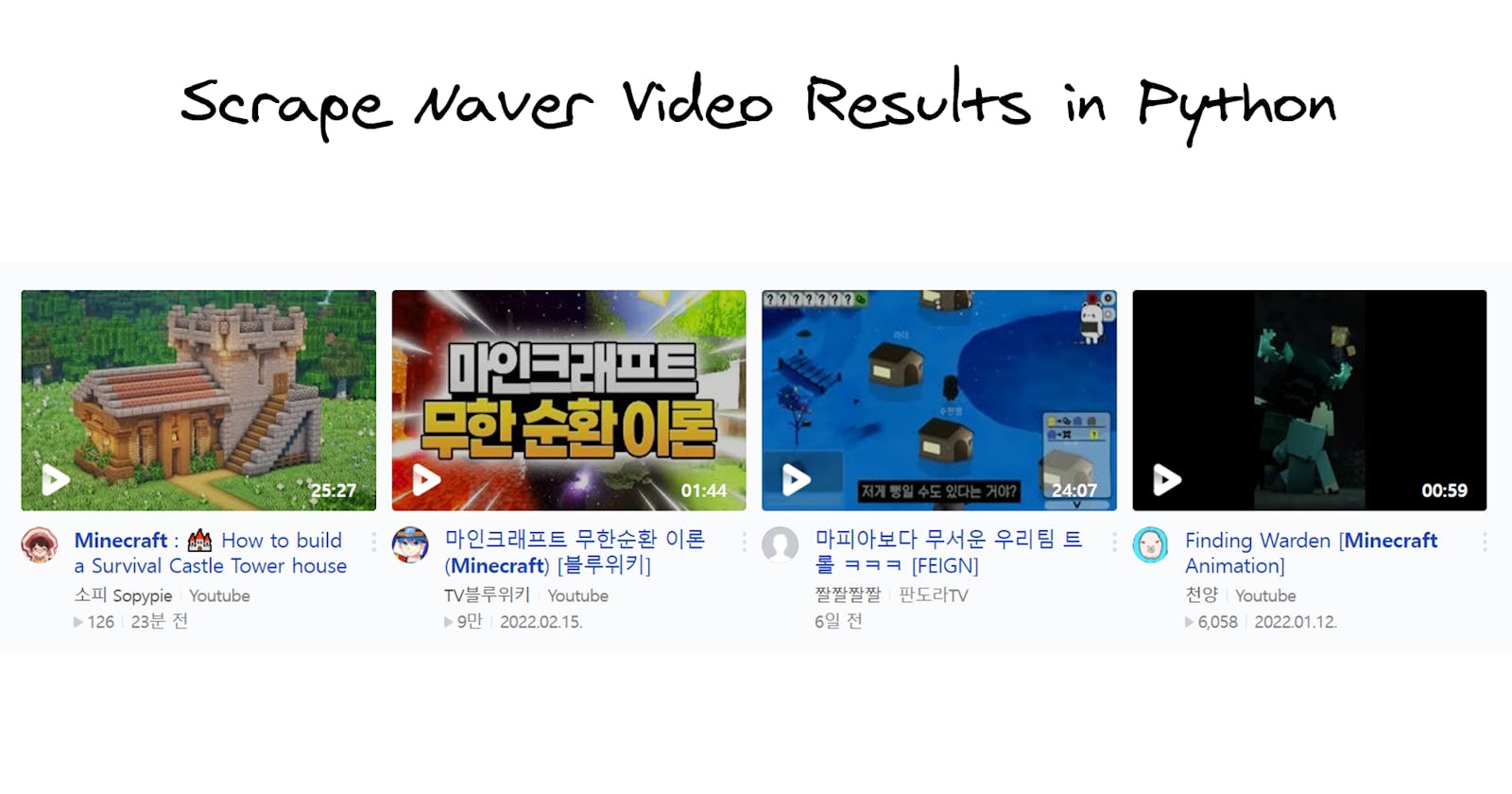
What will be scraped

Prerequisites
Basic knowledge scraping with CSS selectors
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
Separate virtual environment
If you didn't work with a virtual environment before, have a look at the dedicated Python virtual environments tutorial using Virtualenv and Poetry blog post of mine to get familiar.
In short, it's a thing that creates an independent set of installed libraries including different Python versions that can coexist with each other at the same system thus preventing libraries or Python version conflicts.
📌Note: this is not a strict requirement for this blog post rather a reminder.
Install libraries:
pip install requests, parsel
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites.
Full Code
import requests, os, json
from parsel import Selector
def parsel_scrape_naver_videos():
params = {
"query": "minecraft", # search query
"where": "video" # video results
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36",
}
html = requests.get("https://search.naver.com/search.naver", params=params, headers=headers, timeout=30)
selector = Selector(html.text) # very similar to bs4, except parsel supports Xpath
video_results = []
for video in selector.css(".video_bx"):
# https://parsel.readthedocs.io/en/latest/usage.html#using-selectors
title = video.css(".text::text").get()
link = video.css(".info_title::attr(href)").get()
thumbnail = video.css(".thumb_area img::attr(src)").get()
channel = video.css(".channel::text").get()
origin = video.css(".origin::text").get()
video_duration = video.css(".time::text").get()
views = video.css(".desc_group .desc:nth-child(1)::text").get()
date_published = video.css(".desc_group .desc:nth-child(2)::text").get()
video_results.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"channel": channel,
"origin": origin,
"video_duration": video_duration,
"views": views,
"date_published": date_published
})
print(json.dumps(video_results, indent=2, ensure_ascii=False))
Pass search query parameters and request headers:
def parsel_scrape_naver_videos():
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
"query": "minecraft", # search query
"where": "video" # video results
}
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36",
}
Pass URL parameters, request headers, make a request and pass returned HTML to parsel:
html = requests.get("https://search.naver.com/search.naver", params=params, headers=headers, timeout=30)
selector = Selector(html.text) # very similar to bs4, except parsel supports Xpath
Create temporary list to store the data and extract all data:
video_results = []
# https://parsel.readthedocs.io/en/latest/usage.html#using-selectors
for video in selector.css(".video_bx"):
title = video.css(".text::text").get()
link = video.css(".info_title::attr(href)").get()
thumbnail = video.css(".thumb_area img::attr(src)").get()
channel = video.css(".channel::text").get()
origin = video.css(".origin::text").get()
video_duration = video.css(".time::text").get()
views = video.css(".desc_group .desc:nth-child(1)::text").get()
date_published = video.css(".desc_group .desc:nth-child(2)::text").get()
| Code | Explanation |
::text or ::attr(attribute) | to extract text or attriubte value from the node. |
get() | to get actual data. |
Print the data:
# ensure_ascii=False to properly display Hangul characters
print(json.dumps(video_results, indent=2, ensure_ascii=False))
Part of returned data:
[
{
"title": " : 🌲 How to build Survival Wooden Base (#3)",
"link": "https://www.youtube.com/watch?v=n6crYM0D4DI",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2Fn6crYM0D4DI%2Fmqdefault.jpg&type=ac612_350",
"channel": "소피 Sopypie",
"origin": "Youtube",
"video_duration": "24:06",
"views": "671",
"date_published": "4일 전"
},
{
"title": "마인크래프트 무한순환 이론 (",
"link": "https://www.youtube.com/watch?v=kQ7wyG9mShQ",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2FkQ7wyG9mShQ%2Fmqdefault.jpg&type=ac612_350",
"channel": "TV블루위키",
"origin": "Youtube",
"video_duration": "01:44",
"views": "9만",
"date_published": "2022.02.15."
} ... other results
]
Alternatively, you can achieve the same by using Naver Video Results API from SerpApi which is a paid API with a free plan.
The difference is that there's no need to create the parser from scratch, maintain it and figure out how to scale it without being blocked.
import os
from serpapi import NaverSearch
def serpapi_scrape_naver_videos():
params = {
"api_key": os.getenv("API_KEY"), # your serpapi api key
"engine": "naver", # parsing engine
"query": "minecraft", # search query
"where": "video" # video results
}
search = NaverSearch(params) # where data extraction happens
results = search.get_dict() # JSON -> Python dictionary
video_results = []
# iterate over video results and extract desired data
for video in results["video_results"]:
video_results.append({
"title": video["title"],
"link": video["link"],
"duration": video["duration"],
"views": video.get("views"),
"pub_date": video.get("publish_date"),
"thumbnail": video["thumbnail"],
"channel_name": video.get("channel", {}).get("name"),
"channel_link": video.get("channel", {}).get("link")
})
print(json.dumps(video_results, indent=2, ensure_ascii=False))
Part of returned data:
[
{
"title": "Minecraft : 🌲 How to build Survival Wooden Base (#3)",
"link": "https://www.youtube.com/watch?v=n6crYM0D4DI",
"duration": "24:06",
"views": "671",
"pub_date": "4일 전",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2Fn6crYM0D4DI%2Fmqdefault.jpg&type=ac612_350",
"channel_name": "소피 Sopypie",
"channel_link": "https://www.youtube.com/channel/UCCuuRWM5JTvYBnbufwJ4E5Q"
},
{
"title": "마인크래프트 무한순환 이론 (Minecraft) [블루위키]",
"link": "https://www.youtube.com/watch?v=kQ7wyG9mShQ",
"duration": "01:44",
"views": "9만",
"pub_date": "2022.02.15.",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2FkQ7wyG9mShQ%2Fmqdefault.jpg&type=ac612_350",
"channel_name": "TV블루위키",
"channel_link": "https://www.youtube.com/channel/UCQreDC73rqiw1wSc_ZYwgHA"
} ... other results
]
Links
Outro
If you have anything to share, any questions, suggestions, or something that isn't working correctly, reach out via Twitter at @dimitryzub, or @serp_api.
Yours, Dmitriy, and the rest of SerpApi Team.
Add a Feature Request💫 or a Bug🐞